Sistema di analisi e gestione dei Big Data prodotti
Abbiamo realizzato un sistema dimensionato per gestire a regime 120 Terabyte di dati normalizzati per anno. Vista questa mole di dati, si è optato per un’architettura facilmente scalabile in termini di spazio e capacità di calcolo, in particolare il abbiamo realizzato un’infrastruttura che permette di raccogliere, normalizzare ed elaborare i dati provenienti dai vari sistemi.
Attraverso un reverse proxy Linux (nginx) che, oltre a garantire la sicurezza e l’autenticazione sul sistema, permette di gestire i flussi dati in ingresso e applicare le procedure di normalizzazione dei dati. I flussi così normalizzati sono salvati su un file system HDFS condiviso su un cluster di calcolo Linux su cui, attraverso la piattaforma SPARK, vengono generate effettuate le attività di analisi dei dati.
Gli stream implementati riguardano i dati provenienti dal sistema di rilevazione dati sui sistemi client (QUARK) e nei sistemi presenti dalle interazioni dell’utente con gli altri soggetti (ANTARES).
Per ognuno di questi stream sono stati realizzati dei moduli software per l’invio dei dati dai rispettivi sistemi al front end nginx. Le tipologie di analisi implementate sono raggruppabili in:
- Statistiche
- di Clustering/Biclustering
- Pattern Mining
Le attività di analisi vengono fatte utilizzando la piattaforma Spark, leggendo i dati presenti nel file system HDFS, elaborandoli e risalvando i dati in HDFS.
Abbiamo analizzato i processi di parametrizzazione del modello di clusterizzazione con l’obiettivo di trovare una configurazione standard che permettesse di ricavare dei cluster in modo totalmente automatico e stabile nel tempo. Quello che si è evidenziato è che questi algoritmi necessitano, per estrarre dati significativi, di una continua ricerca e manutenzione delle impostazioni. Senza la supervisione di una figura altamente specializzata che conosca la base dati, la dinamica e il significato dei dati analizzati si rischia di avere classificazioni triviali o fuorvianti.
Nelle attività di analisi si trovano spesso dei cluster che apparentemente possono non avere un significato ma, se approfonditi da parte di un data scientist e da un esperto di dominio, hanno notevole significato.
Considerano che l’analisi di questi dati non deve essere fatta in tempo reale ma può essere schedulata, abbiamo introdotto una fase intermedia tra la generazione dei cluster e l’inserimento di tali cluster come attributo alle entità. In questa fase vengono analizzati i risultati prodotti, eventualmente modificate le elaborazioni e, dove se ne veda la necessità, fatte di nuove, in modo da produrre una serie di dati validati e intercettare nuovi cluster che possono nascere nel tempo.
Esempio di cluster basato sull’analisi dei processi utilizzati dall’utente e dalle risorse hardware impiegate. Si vede chiaramente che il sistema ha diviso gli utenti di un sistema centralizzato (Cluster A) dagli utenti di personal device (Cluster B).
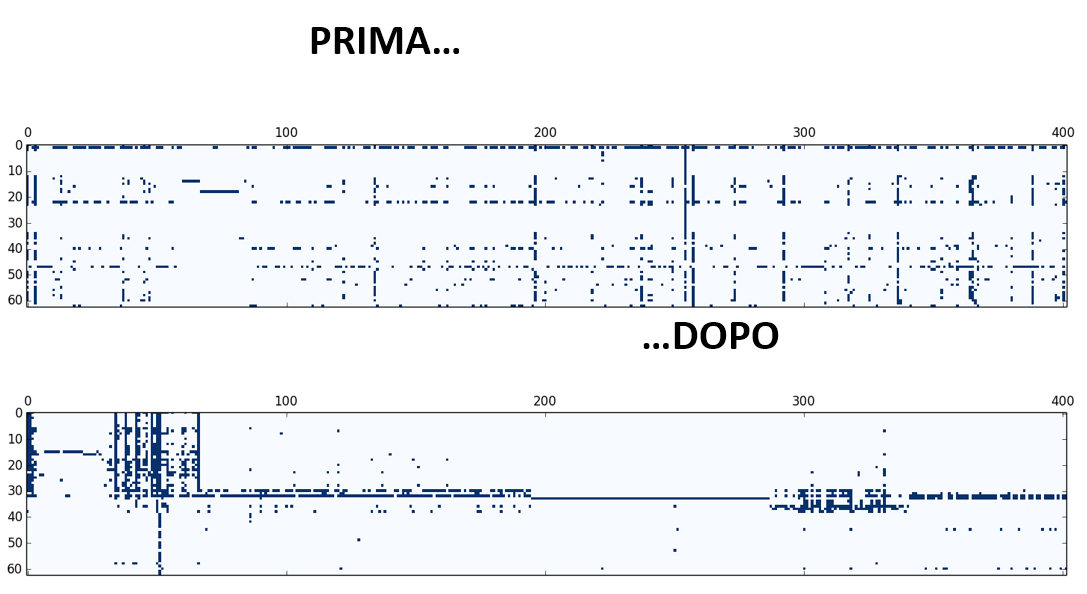
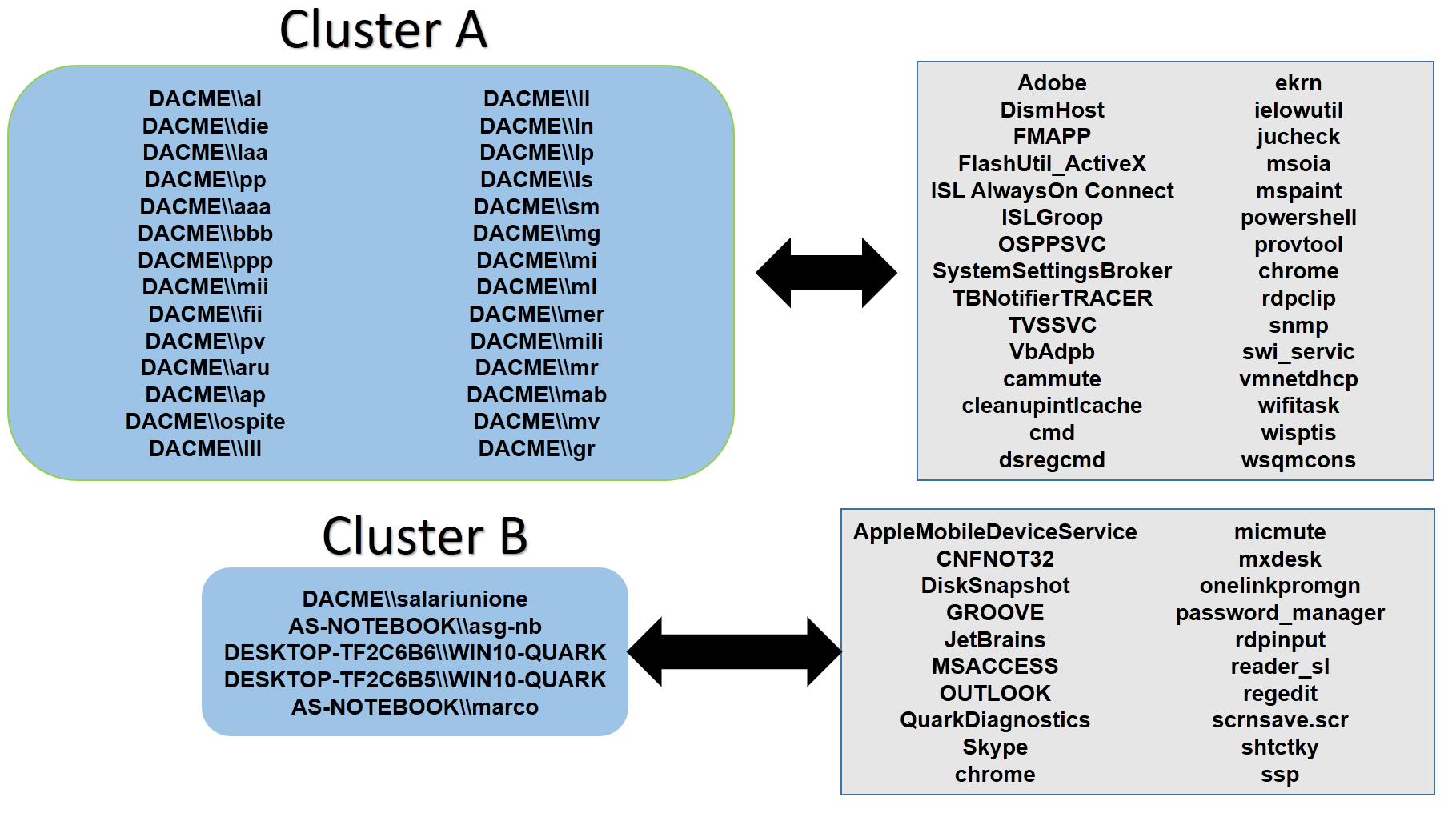
In questa elaborazione vengono divisi gli utenti dagli utenti di sistema in base ai processi utilizzati
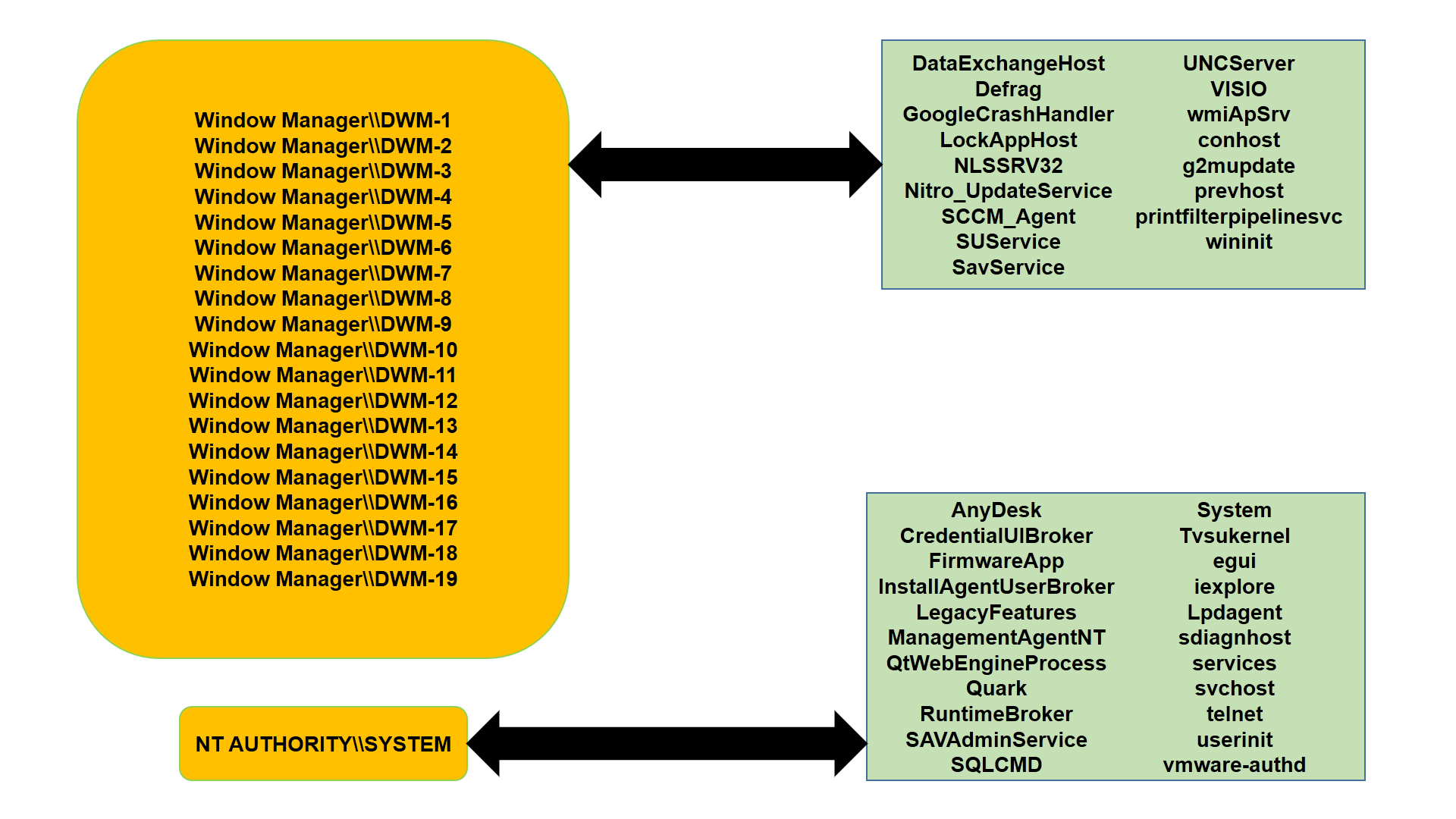
Il codice sorgente degli script di elaborazione e i dati utilizzati per i test sono scaricabili gratuitamente previa richiesta da inviare a saidea@saidea.it